
言語と計算により紡ぐ「新」森羅万象
-1分、-1時間、-1日、-1週間、-1ヶ月、-1年、あまりにも世界の変化が目まぐるしいが故に 「-1 〇〇」に過ごしていた生活環境、アクセスしていた情報環境、そして、考えていたことの根底が揺らいでおり、ここ最近は、妙な脳内フォグが立ち込めている。 情報技術を手法として選択して何かを創ることに生きがいを見出している自分にとっては創ったものが情報空間に消失していく空虚さを強く実感しており、根底以外に基底をも意識しないと脳と身体が乖離してゆらゆらと時間軸のみが進行する状態で、いまさら始まったことではないが、物理現実を痕跡無く浮遊するだけになってしまうのではないか、手元のスマートフォンの画面に表示されている情報は幻覚なのではないか、この話題は、-n 秒の世界と+n秒の世界を隔てる出来事なのではないかと、謎の脅迫観念にも似たような疑問と、気の抜けない状態、論拠や寂念の不足が次から次へと湧いて出てくるのである。 と、数日だけ思っていた。 冷静に考えると、言葉にならない感動を言語で切り取ることができさえすれば、あとは計算機の力を見方にどこまでも表現を拡張できる時代の到来であり、表現者にとっては、「これまでは手に届かなかったあの作り方」「細部に到達するまでの土台づくり」のような点において、時間軸を圧縮できる恩恵は必ず受け取ることができると考えている。 最近、触ってみた主に映像表現に使えるであろう、機械学習、DeepLearning による手法、ツールのうち、個人的に多用するであろうと思っているのが以下の2つ(これもまた+1〇〇後には、-1〇〇では

文脈と身体性を考える年だと思う
2023年の年末から2024年の年初の休み中は、本当にダラダラした. 休みの間には、デジタル機器が身体から離れることはなく、むしろ、Quest3などで遊んだりなどテクノロジー楽観主義に見を委ね、現実にデジタル情報が重畳されたすぐそこにある未来に想いを馳せる時間を過ごしていた. さて、2023年は、様々な方々やメディアが総括するように「生成AI」という言葉が、またたく間に広がり、生成AIとの関係がどうだとか、「共生」や「共創」と言っておけば良いだろうという風潮が何だか溢れかえっていた年だったように思う.表現の均一化、創造性を問う議論、人と機械の対立構造など、泳がせておくには、未だに議論が多すぎるとの認識はありつつも、生成AIは気づいたら作業の隣に存在しており、我々の活動を伴走している. それは視覚表現の巧みさだけではなく、コンセプトやビジョンなど、指示者の指示によっては、より高度で高級な知的活動をも伴走できる存在としてネット空間に鎮座しており、それらに人類が翻弄されるという、新たな時代を迎えたようにも思える. ところで、ネットにアクセスするだけで、虚実に関わらず、”絶え間なく降り注ぐイメージ”が視覚に流れ込み、溢れかえるこの状況は、人間の生物としての特性として(と言って良いのかは定かでは無いが)、視覚優位の我々にとって、現実への認識を負の方向へと変容させる最大の要因になっている可能性がある. 例えば、2023/11/12の日経紙面で報道された「ガザ衝突、偽画像が拡散 生成AIで作成か」のタイトルのニュース(1)のように、偽情報が世論を煽り対立が過激化されるような事例が年々増えている. 偽情報による台湾総統選では既に問題になっているが、これはおそらく今年のアメリカ大統領・議会選挙でも更に加速するのは容易に予想できるだろう. さらに、厄介なことに、偽情報が蔓延すると、真情報を偽情報だと言い張る輩が現れる. 昨年4月、南インドのタミル・ナードゥ州の政治家が、自分の所属する政党が30億ドルの横領に関わっているとして党を糾弾する内容の音声が流出したそうだが(2)、当該の政治家はこれを「機械によって生成されている」としたが、実際には本物の音声だったようだ.このように本物の情報を偽と見なされてしまうことは「嘘つきの配当(liar’s divident)」と呼ばれており、2024年以降、さらにこれが加速すると懸念されている.自分のようなタイプの人間は、偽情報と同様に真の情報に対しても疑心暗鬼になってしまい、自身の内面にしか興味が無くなるということを危惧している. 「情報」とどう向き合うべきなのか、情報リテラシーという言葉では対処できない時代の訪れに、行動と思考の源泉となるは「つくって考えること」しか無いと思ったりしている. こんなことを書きながら、ぼんやり思うのは、「つくって考えること」については、これまで以上に、文脈(Context)と身体性(Embodiment)に鋭敏になることを大切にしたい. この2つに関しては、日々の情報収集と表現活動の両者に関連するのと、前段で触れた真偽が破綻した状況への応答でもあるのだが、 情報収集×文脈の視点については、網羅的に専門家になるということではなく、教養的なものに関しては、情報の前後をふんわり知ること、伝わる情報に編集できることを意識しようかと. 表現活動×文脈に関しては、今更ながらだが、なんとなくこれまでの創作で分かってきたこともあるので、表現、芸術の「史」の延長に位置づけられるように思考を整理していこうと思う. 情報収集×身体性については、可能な限り情報摂取に、何らか身体的経験を取り入れることを大事にしたい.手書き、肌触り.自分の足で経験して口で伝える. 表現活動×身体性については、表現のコンセプトの一部に常に取り入れたく、記号化可能な身体と社会構造の変遷の相関の理解と未知なる記号化された身体性を描くことが1つ(たぶん何言っているかわからないと思うが).もう1つが、A/V表現における身体想起の表現方法を考えたい. ざっと、今年は、こんな感じだろうかね. ※1:「ガザ衝突、偽画像が拡散 生成AIで作成か 100万回以上閲覧の投稿20件 SNSで対立煽る」日本経済新聞、2023年11月12日 ※2:「An Indian politician says scandalous audio clips are AI deepfakes. We had them tested」rest of world、5 JULY 2023 • CHENNAI, INDIA.
カメラと俳句
俳句というものが江戸時代の人びとの場合、記録の枠割を持っていたのじゃないかと思います。とくに旅をした場合、行った先で一句書きとめておく。絵ごころがある人だとスケッチを描くわけですが、俳句にはそういう記録性という実用機能があって、あとでその俳句を見れば旅先の情景なり体験なりを思い出すインデックスになる。いまの日本人は旅行に行くときにはかならずカメラをぶらさげていって、行く先々でパチパチ撮っていますね。あれは昔の人の俳句のかわりだろうと思うんです。 明治メディア考 (エナジー対話) 1979/4/1 前田愛の発言 これは、先日、下北沢のほん吉という古本屋で500円で購入した、小冊子の古書「エナジー対話・明治メディア考」での日本を代表する評論家前田愛と加藤秀俊の対話の一節である。 この一節の通り、カメラと俳句には類似構造があって、まさに写真は現代の俳句だ。 カメラは単純な光学機械に過ぎないが、写真には人の主情が混じっており、俳句における時間軸を決定する季語は、写真においては、例えば、柿の木とその向こうの夕暮れであり、桜の花が散る様子、月が雲に隠れる瞬間など、短い時間の中での美しさや哀しさである。 テキストと画像。異なるメディアではあるものの本質的には同じであり、俳句は詠むものがその場で捉えた情景のスチール写真なのだ。 日本文化特有の表現として面白い点の1つが、こういった離散的に時間を切り取るところにある。 日本の伝統的な詩や文学には、簡潔に情景や情感を伝える技法が求められ、俳句や川柳など、少ない言葉で深い意味を持たせる詩的表現が好まれる背景には、省略の技法や間(ま)という概念がその根底にはある。 さらに視野を広げて、俳句以外にも、目を向けてみると、能における鼓のポンと入る音、歌舞伎における見得などにも共通項がある。 視聴覚を使って、空間と時間を一瞬、停止させることで、その瞬間のドラマや美が際立てられる。これは、連続する時間の中で一つの瞬間を切り取り、観客の注意をその点に集中させる技法とも言える。 このような感性や価値観は、日本特有の日常生活や自然との関わりの中で培われ、伝統的な芸術や文学においても色濃く反映されていることが分かる。 今日におけるニューメディアを活用した表現方法にも継承されるべきであり、制作において頭の片隅に置いておきたいと思った。
Resolume と UnrealEngine5を連携させてオーディオリアクティブな表現をしたい
気づいたら 2022年もあと10日弱。 自主制作においても様々な挑戦をする機会を頂くことができ、非常に充実した1年でした。 12月21日に予定していたイベントはやむを得ない事情で出演ができなかったことだけ悔いは残っておりますが、やり切った感は十分にあります! さて、仕事も落ち着いてきたので、自主制作の振り返りをしたいと思います。 今年、挑戦したのは、 UnrealEngine の作品への活用です。 6月に出演させて頂いた Hyper geek #3 では、全て Unreal + Resolumeで制作をしていたのですが、どう制作していたのか聞かれることがありましたので、土台としていた技術部分について簡単に解説しておこうかと思います。 (動画を見返して、映像がだいぶ白飛びしていたので、Post processing とかもっと考えないとなあと思ったり

暴走しがちな技術を目の前にコンヴィヴィアリティについてぼんやりと考えている
世界は変化している.21世紀を迎えた人類は,利便性に堕してバランスを逸したモダニズムに,ようやくブレーキをかけつつある.そして,現在,私達の生活空間は,モバイルに象徴されるメディア技術によって,ヴァーチャルなインフラストラクチャーと接続し,新たなリアルを獲得した.しかし,この生活圏は,あまりにも可塑性が高く,過剰に生成し,暴走しがちなのだ.私達は,見えない時空間を再構築する,メディア表現を必要としている.こうした事態に,いま私たちが掲げるキーワードは,バランスの復権だ.人類最古の発明のひとつである車輪にペダルが装着されたのは,19世紀である.私たちは,モダニズムのはじめに立ち戻り,ハイ・テクノロジーと身体が駆動してきたバランス感覚に着目する.自転車は,理性と野生,都市と自然,ヴァーチャルとリアルを接続し,シンプルなバランスの循環を見出す指針となるだろう.「クリティカル・サイクリング宣言」より,情報科学芸術大学大学院(IAMAS)赤松正行教授 様々なテクノロジーを活用して仕事や制作をする私にとって「お前は,テクノロジーに使役されていないか?」は,タスクに追われている時こそ,冷静に自分自身に投げかけている大事な問いである. 上記は,IAMASの赤松教授を中心に行われている「クリティカル・サイクリング宣言」の引用である。キーワードである「バランスの復権」は,ここ数年の趨勢を踏まえると頭の片隅に置いておきたい言葉の一つである. 我々は火を手に入れた時から,テクノロジーととも共生し自身の能力を拡張させてきた。一方で、現代においては、共生というよりテクノロジーに依存しているという状態の方が肌感がある人が多いのではないだろうか. テクノロジーを捨てて,テクノロジーに頼らない生活を強要する話でもなく,あくまでバランス良く共生するにはどうすればいいんだろうかとぼんやり考えている. テクノロジーに依存し,テクノロジーに操作され,テクノロジーに隷属していないか. テクノロジーとのちょうど良い関係ってなんだろうか. 人が本来の人間性を失うことなく,創造性を最大限に発揮するためにはどのようにテクノロジーと付き合っていけば良いのか. こんな疑問とともに,今更ながら、振り返り始めたのが,イリイチの「コンヴィヴィアル」という概念である. コンヴィヴィアルそのものは,特に真新しい概念でもないが,最近,様々な人が議論に取り挙げているなと思っていた. 完全に脳の隅っこに置き去りにしていたのだが,ちゃんと調べてみると,確かに大事な視点は書いてある、という印象であった. コンヴィヴィアルってなんぞやと思う方が大半だと思うので,イリイチが自身の著書「コンヴィヴィアリティのための道具」の内容を備忘としてまとめておきたい. ブラックボックス化された道具が我々の創造的な主体性を退化させる イリイチは,「人間は人間が自ら生み出した技術や制度等の道具に奴隷されている」として,行き過ぎた産業文明を批判している.そして,人間が本来持つ人間性を損なうことなく,他者や自然との関係のなかで自由を享受し,創造性を最大限発揮しながら,共に生きるためのものでなければならないと指摘した.そして,これを「コンヴィヴィアル(convivial)」という言葉で表した.最もコンヴィヴィアルでは無い状態とは,「人間が道具に依存し,道具に操作され,道具に奴隷している状態」である. では,コンヴィヴィアルなテクノロジーとは? イリイチは,その最もわかりやすい例として,「自転車」を挙げている.自転車は人間が主体性を持ちながら,人間の移動能力をエンパワーしてくれる道具の代表例といってもいいだろう. さて,周りや自身の生活を鑑みてみよう.現状,我々は様々なテクノロジーに囲まれ,その恩恵を受けて生活をしている.例えば,たった今,私は,blog ツールを使って,本件について備忘を残しているところであるが,このツールの裏側の仕組みなど全く気にすることなく,文章を書くことができている.このように,ブラックボックス化された道具のおかげで,我々は不自由を感じることなく創造的な活動をできているのだ.一方,不自由を感じなくなればなるほど,ここをこうしたい,もっと別のものがあればいいのになどの,創造的な発想が生まれなくなる.言い換えると,自らが,新しい道具を作り出そうとする主体性が失われていくのであるとイリイチは指摘する. ここで疑問が湧く. では,「人間の自発的な能力や創造性を高めてくれるコンヴィヴィアルな道具」と「人間から主体性を奪い奴隷させてしまう支配的な道具」を分けるものは一体何なのか? 二つの分水嶺と分水嶺を超えて行き過ぎていることを見極めるためには イリイチは,「人間の自発的な能力や創造性を高めてくれるコンヴィヴィアルな道具」と「人間から主体性を奪い奴隷させてしまう支配的な道具」を分けるものが,1つの分岐点ではなく,2つの分水嶺であると述べている. ここについては抽象的な議論であることは否めないが,ある道具を使う中で,ある1つの分かれ道があるのではなく,その道具が人間の能力を拡張してくれるだけの力を持つに至る第1の分水嶺と,それがどこかで力を持ちすぎて,人間から主体性を奪い,人間を操作し,依存,奴隷させてしまう行き過ぎた第2の分水嶺の2つの分水嶺であるとした.不足と過剰の間で,適度なバランスを自らが主体的に保つことが重要なのである. では,道具そのものが持つ力が「第二の分水嶺」を超えて行き過ぎているかどうかを見極める基準はどこにあるのか? この問いに対して,イリイチは6つの視点を挙げており,それらの多次元的なバランス(Multiple Balance)が保たれているかどうかが重要であるとしている. 多元的なバランス(Multiple Balance) を確認するための5つの視点 生物学的退化(Biological Degradation) 「人間と自然環境とのバランスが失われること」である.過剰な道具は,人間を自然環境から遠ざけ,生物として自然環境の中で生きる力を失わせていく. 根源的独占(Radical Monopoly) 過剰な道具はその道具の他に変わるものがない状態を生み,人間をその道具無しには生きていけなくしてしまう.それが「根源的独占」である.これはテクノロジーだけではなく,制度やシステムの過剰な独占も射程に入るとしている.風呂にスマホを持ち込むなどの行動はかなり,典型的な例として挙げられるだろう. 過剰な計画(Overprogramming) 根源的な独占が進むと,人間はどの道具無しではいられない依存状態に陥るだけではなく,予め予定されたルールや計画に従うことしかできなくなってしまうのである.効率の観点で考えると計画やルールは重要だが,過剰な効率化は,人間の主体性を大きく奪い,思考停止させてしまう.「詩的能力(世界にその個人の意味を与える能力)」を決定的に麻痺させるのだ. 二極化(Polarization) このような根源的独占や過剰な計画が進むと,独占する側とされる側,計画する側とされる側の「二極化」した社会構造を生む.無自覚なままに独占され計画された道具に依存し,人間が本来持っている主体性が奪われていくのだ. 陳腐化(Obsolescence) 道具は人間によって更新を繰り返していく.より早く,より効率的にといった背景で,既存の道具は次々と古いものとして必要以上に切り捨てられていないか? フラストレーション(Frustration) 道具がちょうど良い範囲を逸脱して,第二の分水嶺を超えて上記の5つが顕になる前触れは,個人の生活の中でのfrustrationとして現れるはずだと述べている.違和感を敏感に察知するためのアンテナを持つことが重要であり,アンテナを敏感にすることで,上記の脅威を早期発見することができるとイリイチは言う. バランスはどのようにして取り戻すのか 人間と道具のバランスを取り戻すための方法として,イリイチは「科学の非神話化」という考え方を残している.これは,言い換えるとテクノロジーをブラックボックス化しないということである. ブラックボックス化されたテクノロジーは我々をテクノロジーへの妄信や不信を招き,自ら考え判断し意思決定する能力を徐々に奪っていく.極端な例だが,物理学者のリチャード・ファインマンは「What I Cannot Create, I Do Not Understand.」と言ったように、分かることとつくることの両輪で考えている状態が人間と道具のバランスが保たれている,つまり,人と道具の主従が理想の状態といえるのではないだろうか. とは言えども,これはそう簡単なことではない. つくるまではいかなくても,つくるという状態の根底にある「なんで世界はこうなっていないのだろう・・」や「こうあればいいのにな・・」といった、ちょっとした違和感や願望を持つことぐらいで良いのではないか,もいうのが私の意見である. これからもテクノロジーは目まぐるしく変化していく,もちろん何もしなくてもテクノロジーと共に生きてはいけるが,気づかぬ間に現時点の自身はテクノロジーにより制され,自らも意図せぬ状態へと変わってしまっていることもあるだろう(分かりやすいのがSNS中毒など) ガンジーの言葉の「世界」を「テクノロジー」と置き換えて参照すると,テクノロジーによって自分が変えられないようにするために,自ら手を動かすことはやめてはいけないと感じる.そして,それができる方々は是非,その心を持ち続けてほしい. あなたがすることのほとんどは無意味であるが、それでもしなくてはならない。それは世界を変えるためではなく、 世界によって自分が変えられないようにするためである。Mahatma Gandhi 日々の生活の中で,自分自身の認識と世界とのギャップを見過ごさずに,自らが積極的に世界に関わり,時には,つくるという手段を通して世界に問いを投げかける.このような態度を保ち続けたいと改めて思ったのであった.
オーディオ・ビジュアルアートついてそろそろ深く考える時期にきているという話
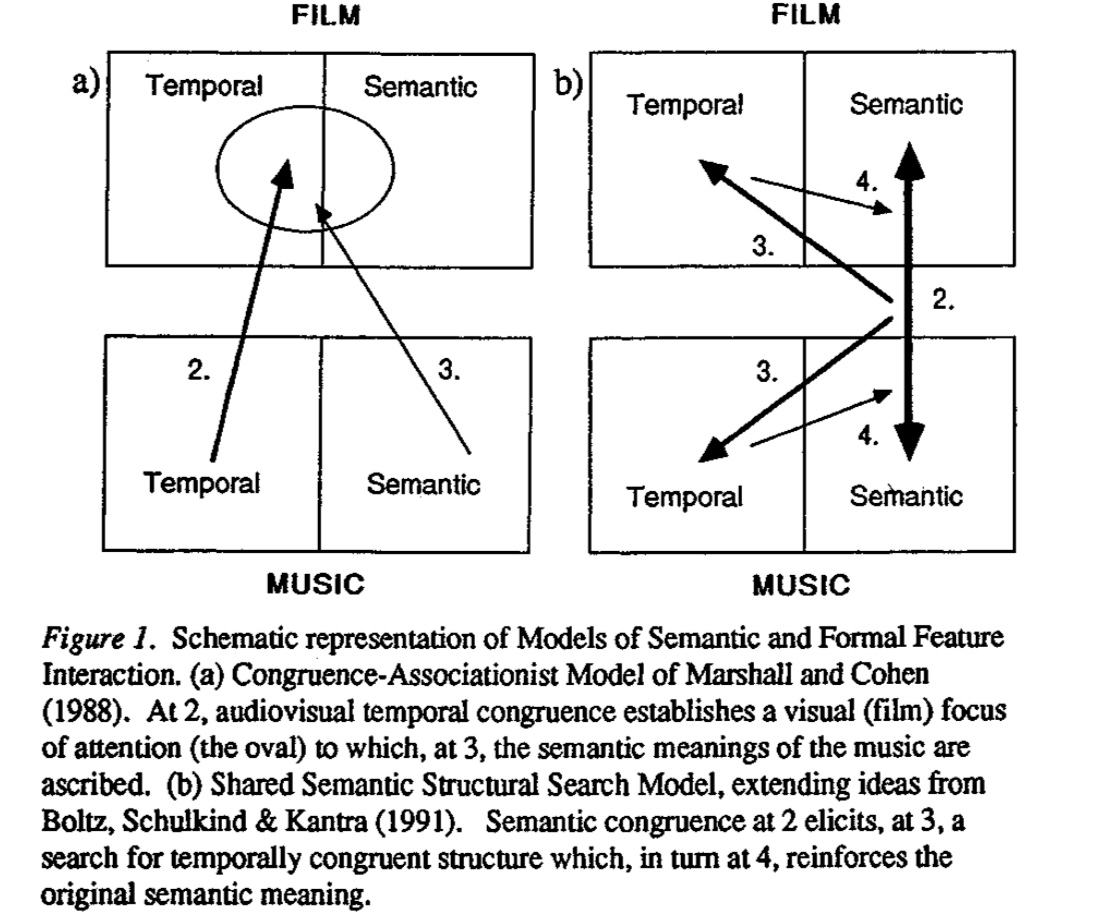
12月は、「視覚×聴覚」を掛け合わせた芸術表現、言い換えると「オーディオ・ビジュアルアート」作品(とりわけパフォーマンス領域における)に触れる機会が多かったのだが、作品を観ながら、個人的にオーディオ・ビジュアルアートに対する論を整理する必要があると思い始めたので、このようなタイトルで投稿をしている。 そもそも何故そんなことを思ったかと言うと、最近、自身の作品制作を通じて、ビジュアル側がオーディオの気持ちを掬い取れていない、オーディオとビジュアルの対立が生じている、その結果、「違和感」が先行することが多かった、という非常に個人的な経験が根底にある。 違和感の根底にあるのはなんだったのか、視覚と聴覚刺激の対立ではなく、調和や共鳴、その条件とは一体何なのか?制作者の感性を超えた論に展開することができるのだろうか、という疑問が沸いて出てきている。 ― 私自身、個人的な活動として、ゲームエンジンなどを活用してオーディオ・ビジュアルアートを趣味として実践する身であるが、過去に鑑賞した作品や技術の制限の元で実験的に表現を作ることが多く、自身の制作に対する考えを言語化可能なレベルには到底及んでいない。 そろそろ、闇雲にオーディオ・ビジュアルアート の実験をするフェーズから、次のフェーズに移行したい。もう少し、言葉を付け加えると、自分なりに オーディオ・ビジュアルアート に対する一本の論を持って実践したいと考え始めており、そのさわりとして、今回、この投稿で keyboard を走らせている―。 オーディオ・ビジュアルアート とは何なのか(W.I.P) オーディオ・ビジュアルアート と聴いてどのようなイメージが皆さんは浮かぶだろうか。 以下の動画は、私自身が尊敬する3人のアーティストの作品である。私が頭に浮かぶ「 オーディオ・ビジュアルアート 」とはこのような視覚情報と聴覚情報に同時に刺激が提示される表現のことを指しているのだが、一般的な定義はもう少し広義であるようだ(wikipedia 以外の定義を探したものの信頼できるリソースが無いという事実を知る) Audiovisual art is the exploration of kinetic abstract art and music or sound set in relation to each other. It includes visual music, abstract film, audiovisual performances
Unity HDRP の Camera の背景色をスクリプトで変更する
これだけなのに,HDRP ではない template のノリで backgroundColor 指定したら,全く動かなくて数時間を無駄にした. HDRP で Camera の背景色を変更したい場合には,以下のようにしましょう.

ライターの欲望と街の受容性について
上京してから早くも4年が経とうとしているのだけれども、都内で時を重ねれば重ねるほど、課題意識が膨らんでいくのが、ライティング周辺で起きていること。ライターの欲望に対する街の受容性については、ここ数年で何も進展が無いように感じる。 むしろ宮下公園のリーガルウォールが実現しなかったことを初めとした”逆行”とも言える話題は尽きない。 一方で、千葉の市原湖畔美術館でのSIDECOREの展示や美術手帖でのグラフィティ特集号は、芸術の制度の延長上で捉え直されつつあるポジティブな兆候であるとも言える。 上の写真はFranceに展示に行ったときに訪れた L'Aérosol 。 誰もが建物全体にライティングできるスポットで、ストリートカルチャーをテーマとした美術館も併設されており、パリ市民のカルチャースポットの一つとなっている。渋谷にもこういう場所がほしい。 "落書き"か"芸術"かを中心とした議論をよく耳にする。その議論の延長線上として、ライティングという行為の街の受容性の評価や、ライティングと都市の共存を都市計画へと組み込むための諸手法の整理は、まだまだ発展途上だ。 慎重な議論と整理が今後も必要であろう
Unity AR Foundation についてのメモ
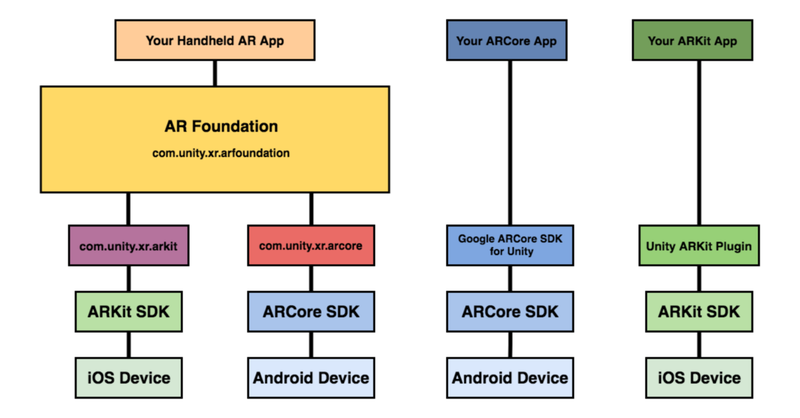
はじめに 最近,慣れ親しんでいるUnity で AR コンテンツを作ってみたくなり,色々と下調べしたのでメモを載せておきましょう. 最終的にやりたいことは AR オーディオビジュアライゼーション。 前に投稿したLASPとVFXGraphでオーディオ・ビジュアル作る、みたいなことをARアプリで作ってみたいというのがモチベーションです (※ 2020/5/3時点で実現はできていません ⇒ 2020/5/6 無事完成) さて、UnityのAR開発環境についてですが,Unity ARKit Pluginが2019年6月で非推奨になったので,ARKit3 以降,Unity上でのAR開発は,AR Foundationを活用するのが良いでしょう. https://www.youtube.com/watch?v=dYlndpzNqwk AR Foundation とは AR Foundation自体は開発者へインターフェースを提供しているだけで,AR機能自体は実装していません.ARKit XR Plugin on iOS や ARCore XR Plugin on Android などは別途必要になってきます. で,どんなことできるのかというと、マニュアルにもあるように,以下のような技術を提供しているようです. World Tracking:現実空間内(物理空間内)でのデバイス位置の認識と向きの追跡をします.平面検出:水平面と垂直面を検出します.点群:特徴点を検出する.アンカー:デバイスが追跡する任意の位置と向きを検出する.Light Estimation:物理空間における平均的な色温度と明るさを推定する.Enviroment Probe:Unity 内にキューブマップを自動的に作成する.フェイストラッキング:人の顔を検出して追跡する.画像トラッキング:2D画像を検出して追跡する. 基調講演を見ると何ができそうか良い感じにイメージができますね. https://youtu.be/DUUthDpiGiA 公式からサンプルが公開されているので,慣れ親しむには,これを見ていくのがいいでしょう. 以下のようなサンプルが公開されています. 平面検知:Plane Detection環境光推定:Light Estimate画像トラッキング: Image Tracking物体トラッキング:Object Tracking空間共有:World Map顔認識: Face Trackingモーションキャプチャ:Body

音に反応する AR マスクをサクッとつくる | Audio Reactive FaceMask with AR Foundation
※ 2020/8/1時点での動作検証になります.今後の Unity のバージョンアップなどにより再現できない可能性が点はご留意ください. こんにちは.やっと梅雨が明けたようで,蝉も絶好調ですね. 1週前は早く梅雨明けてくれと項垂れていましたが,すでに夏の日差しに敗北しつつあり,さっさと秋にならないかなと思ったり・・ そういえば,1年前の夏に何をエントリーしていたか振り返ってみると,「」した.毎年,夏の到来後,早々に暑さに敗北している己はだいぶ虚弱です.数年後の夏とか,到来とともに死ぬのではないかと思ってしまう. まあでも,夏に Active に外で遊ぶのではなく,毎年,技術力 UP に集中して取り組めるのでそれはそれで良いのではないかと考えている. と,しょうもない前書きが長くなってしまったが,ここでは、Unity AR Foundation を使って Audio Reactive な AR マスクをつくる方法について触れます.Unity AR Foundation については、前に書いたこちらを参考までにご参照ください. やりたいことのおさらい では,早速,実装について触れていきましょう.と,その前にゴールとゴール達成のための検討ポイントを書いておきます(ここからの内容ですが,AR Foundation に慣れ親しんでいる前提で記載していきますので,不明点などあればお気軽にご連絡ください) 今回の検証環境は以下のような感じです. Unity:2019.3.0f6 PersonalAR Foundation:3.1.0 - preview.4ARKit XR Plugin:3.0.0 - preview.4ARKit Face Tracking:3.0.1検証機器:iPad Pro (第2世代)検証機器(OS version):iPadOS 13.6 今回のゴールは,「音量に応じて顔に貼り付けるテクスチャを変更する」です。 実装していくにあたって,巨人の肩に乗ってしまえということで,ベースのプロジェクトは Dilmer Valecillos さんの github にある「Face Tracking Generating