
言語と計算により紡ぐ「新」森羅万象
-1分、-1時間、-1日、-1週間、-1ヶ月、-1年、あまりにも世界の変化が目まぐるしいが故に 「-1 〇〇」に過ごしていた生活環境、アクセスしていた情報環境、そして、考えていたことの根底が揺らいでおり、ここ最近は、妙な脳内フォグが立ち込めている。
情報技術を手法として選択して何かを創ることに生きがいを見出している自分にとっては創ったものが情報空間に消失していく空虚さを強く実感しており、根底以外に基底をも意識しないと脳と身体が乖離してゆらゆらと時間軸のみが進行する状態で、いまさら始まったことではないが、物理現実を痕跡無く浮遊するだけになってしまうのではないか、手元のスマートフォンの画面に表示されている情報は幻覚なのではないか、この話題は、-n 秒の世界と+n秒の世界を隔てる出来事なのではないかと、謎の脅迫観念にも似たような疑問と、気の抜けない状態、論拠や寂念の不足が次から次へと湧いて出てくるのである。
と、数日だけ思っていた。
冷静に考えると、言葉にならない感動を言語で切り取ることができさえすれば、あとは計算機の力を見方にどこまでも表現を拡張できる時代の到来であり、表現者にとっては、「これまでは手に届かなかったあの作り方」「細部に到達するまでの土台づくり」のような点において、時間軸を圧縮できる恩恵は必ず受け取ることができると考えている。
最近、触ってみた主に映像表現に使えるであろう、機械学習、DeepLearning による手法、ツールのうち、個人的に多用するであろうと思っているのが以下の2つ(これもまた+1〇〇後には、-1〇〇では…と思っているのだろうが)
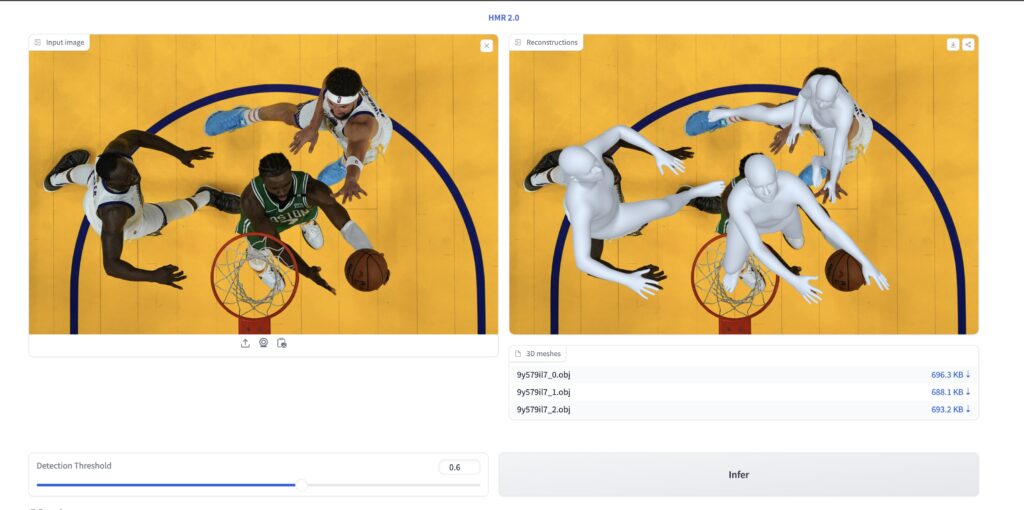
- ShubhamらによりICCV2023で「Humans in 4D: Reconstructing and Tracking Humans with Transformers」の題で発表された単眼カメラで撮影されたビデオから人物のモーションをトラッキングできる手法であり、Blender addon としてCeb 4D Humans が公開されている。
- Zhengyiらにより、arxivで公開された「CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model」は、わずか10秒で入力した画像から3Dモデルを再構成する技術。ComfyUI-3D-Packなどで公開されている。
- Yicong らの「LRM: Large Reconstruction Model for Single Image to 3D」が参照されている、Tripo AI と Stability AIによる、TripoSRも、数秒で入力した画像から3Dモデルを再構成する。
Humans in 4D は、かなり高精度にポーズ推定していることが分かる。
CRMとTripoSRに関して、作り手からするともう一歩ということで、これは学習データ依存の話だと思うが、ほしいモデルによっては完全にディティールが欠如された形状で出力されるのでもうちょっと精度が欲しいところ(パラメータで工夫可能なのかもしれないが)
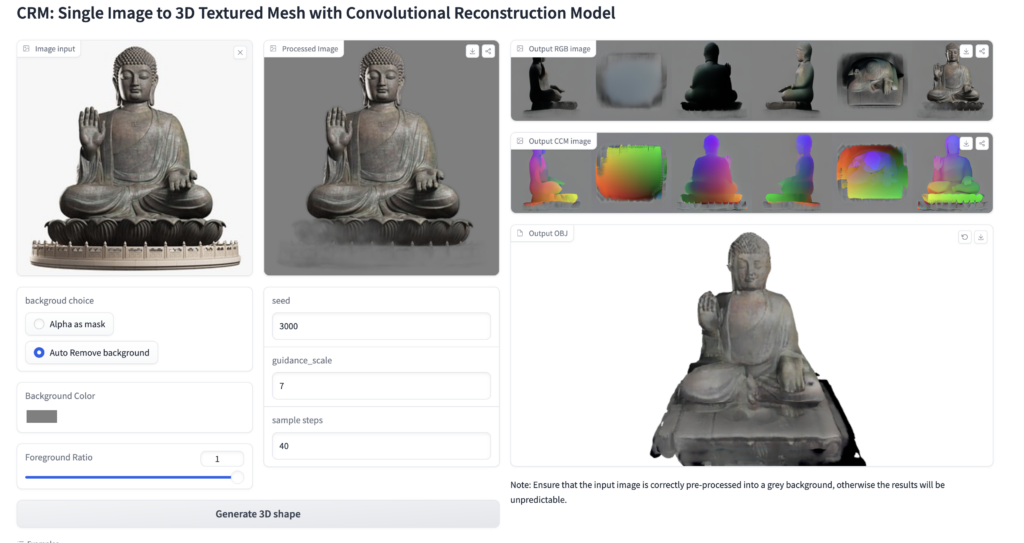
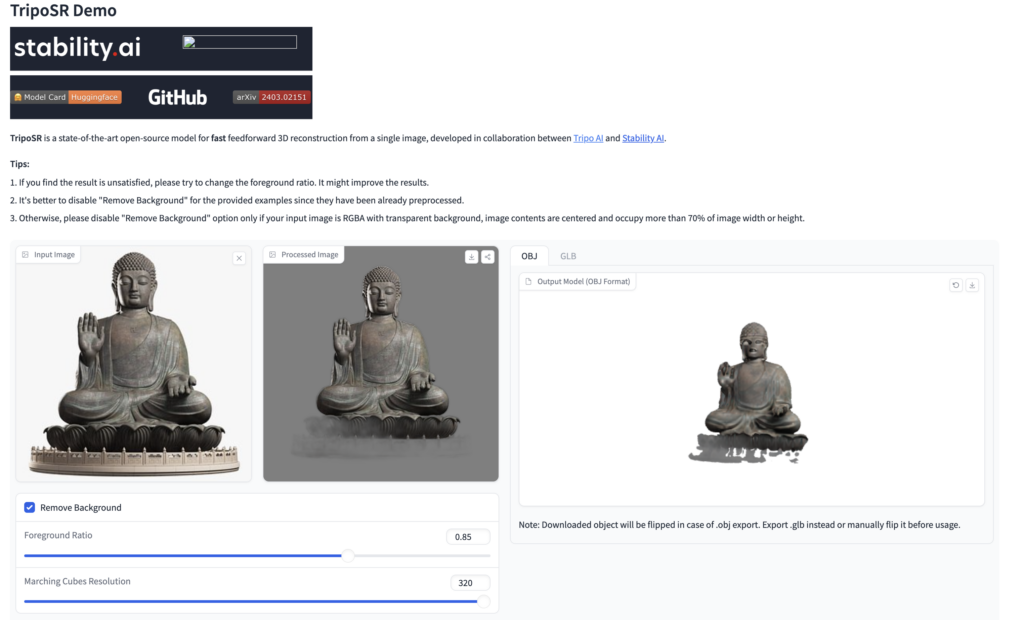
このように物理世界のモノを情報空間上で再構成することが非常に簡単になってくるので、ワークフローさえ確立してしまえば、これまで死んだ空間と切り捨てられてしまったVR空間だとか、工数と時間の都合で細部まで手の届かなかった映像制作に有効活用できる気がしている(まだ実践していないので気がしているだけ)
これらはあくまで手段なので、ただ使うだけでももちろん良いが「言葉にならない感動を言語で切り取る」ことを経て、学習データに基づいた優等生的出力から逸脱する方法を考えていきたい。
この過程で、作り手ならではの個性が拡張し、作り手自身の想像の範疇をも超えた、言葉と計算による紡ぐ「新」森羅万象、つまるところ、言葉にならないあらゆる表象までもが具現化され、そして包容された新世界訪れ、その兆しを掴める気がしている。


